王瑞华 宋薇

摘要:随着篮球赛事的广泛开展,传统数据处理分析已不能满足篮球运动训练指标优化和培训状态评估需求,制约了篮球数据的数字化管理与发展进程。本文基于Spark框架与云计算pyspark接口技术构建数据计算平台,通过统计网站与Scrapy抓取框架获取运动数据,利用Logistic Distribution与ELO算法实现成绩预测,提高篮球运动大数据运算与分析的效率。为运动员、教练员、体育运动管理者提供教学训练与竞赛决策支持。
关键词:篮球 数据分析 Spark ELO
Research on Basketball Performance Prediction Analysis Based on Spark Framework and ELO Algorithm
WANG Ruihua1 SONG Wei2
(Hubei Open University,Wuhan,Hubei Province,430074 China; Wuhan Sports University, Wuhan,Hubei Province,430079China)
Abstract:With the extensive development of basketball events, traditional data processing and analysis can no longer meet the needs of basketball training index optimization and training status evaluation, which has restricted the digital management and development process of basketball data. This paper builds a data computing platform based on Spark framework and cloud computing pyspark interface technology, obtains sports data through statistical website and Scrapy grab framework, and realizes performance prediction by Logistic Distribution and ELO algorithm, improving the efficiency of basketball big data operation and analysis. Provide teaching training and competition decision support for athletes, coaches and sports managers.
Key Words:
Basketball; Date analysis; Spark; ELO
研究背景
隨着篮球赛事的广泛开展,传统数据处理分析方法已无法实现篮球运动数据的深入挖掘与分析需求,制约了训练指标优化和运动员训练状态评估的数字化管理进程。篮球运动数据分析研究,也因此成为体育统计方向的研究[1]。当前篮球运动大数据分析存在以下问题。
(1)缺乏对数据计算分析平台与框架的应用研究[2]。随着计算机存储设备与运动数据采集设备功能日益强大,篮球运动数据存储量与计算量都在不断飞速增长,目前的数据分析平台无法满足篮球运动大数据分析需求[3]。
(2)缺乏对深度学习建模与机器学习算法研究,局限于个别动作数据查询和竞技水平统计描述,对数据的挖掘与分析不够深入,无法提供篮球运动信息预测与策略支持[4]。
(3)缺乏对数据可视化技术的运动训练应用研究,当前运动数据可视化技术主要应用于体育新闻传播[5],着重娱乐性和趣味性,而用于运动训练领域的可视化工具对人工操作依赖程度较高,因此存在可视化结果输出效率低等问题[6]。
研究方法
2.1构建Spark大数据分析开源计算平台
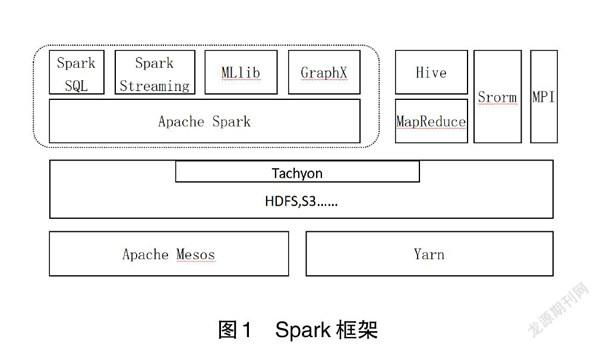
Hadoop MapReduce技术广泛应用于篮球运动大数据平台,但由于MapReduce需要将任务产生的中间结果写回磁盘,需要从网络中的各个节点进行数据拷贝,耗费大量的时间在网络磁盘输出过程中。因此Hadoop MapReduce技术实现大数据分析与计算的运算速度有限,只适合离线的数据计算任务,从而制约了篮球运动数据实时分析与计算。为解决此问题,美国加州伯克利AMPLAB提出基于Hadoop MapReduce开源接口的并行计算框架Spark。Spark框架直接在内存中保存中间运行数据结果,因此进一步提高了大数据挖掘与分析中的数据迭代算法计算效率。如图1所示,Spark平台支持多场景的通用大数据计算,用于解决批处理与交互查询等核心问题,数据的存储在生产环境中由Hadoop分布式文件系统HDFS承担。Spark可以从多数据源读取数据,并且拥有不断发展的机器学习库和图计算库供开发者使用。
2.1.1弹性分布数据集RDD
为避免计算的中间结果会被重复使用,Spark提供了基于RDD cache机制和checkpoint机制来支持容错。通过将RDD数据集的操作结果缓冲到内存中,并直接从内存中输入下一次操作,从而省去了大量Map Reduce磁盘操作,提升了机器学习中迭代算法与交互式数据挖掘的计算效率。本文以文件形式从Hadoop文件系统生成RDD,通过RDD的to DebugString来查看其递归的依赖信息,核心代码如下:
// 创建RDD
def RDDtextFile(path:
String, minSplits:
Int = defaultMinSplits):
RDD[String] = {
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable],
classOf[Text], minSplits) .map(pair => pair2.toString) }
// 创建HadoopRDD
new HadoopRDD(this, conf, inputFormatClass, keyClass, valueClass, minSplits)
2.1.2 pyspark接口应用
依据计算需要,Spark内核会绘制一张计算路径有向无环图(DAG)。基于DAG图,Spark内核将计算过程划分成任务集stage,然后将stage任务提交到计算节点实施计算。基于Spark框架下Python编程接口pyspark实现python与java的互操作,核心代码如下:
from pyspark import SparkContext
sc = SparkContext("local", "MyPySparkJob Name", pyFiles=["MyPySparkFile.py", "MyPySparklib.zip", "app.egg"])
words = sc.textFile("/user/MyPySparkshare/MyPySparkdict/words")
words.filter(lambda w:
w.startswith("spar")).take(5)
2.2.篮球运动数据获取
2.2.1使用统计网站數据
获取Basketball Reference.com网站数据[6],包括:每支队伍平均每场比赛的表现统计;每支队伍的对手平均每场比赛的表现统计;综合统2019-2020年NBA常规赛以及季后赛的每场比赛的比赛数据。使用的是以下三个数据表格。
Team Per Game Stats:每支队伍平均每场比赛的表现统计,包括排名、参与场数、平均比赛时间、投球命中次数(三分球、二分球、罚球)、投篮次数、投球命中率、篮板球总数、助攻、抢断、封盖、失误、犯规、得分。
Opponent Per Game Stats:所遇到的对手平均每场比赛的统计信息,所包含的统计数据与 Team Per Game Stats 中相同,只是代表的是该球队对应的对手的统计信息。
Miscellaneous Stats:综合统计数据,包括排名、队员的平均年龄、胜利次数、失败次数、基于毕达哥拉斯理论计算的赢的概率、基于毕达哥拉斯理论计算的输的概率、(添加)赢球次数的平均间隔、评判对手选择与其球队或是其他球队的难易程度对比(0为平均线,可以为正负数)、每100个比赛回合中的进攻比例、每100个比赛回合中的防守比例、48min内大概会进行多少个回合、罚球次数所占投篮次数的比例、三分球投篮占投篮次数的比例、二分球、三分球和罚球的总共命中率、有效的投篮百分比(含二分球、三分球)、每100场比赛中失误的比例、球队中平均每个人的进攻篮板的比例、罚球所占投篮的比例、对手投篮命中比例、对手的失误比例、球队平均每个球员的防守篮板比例、对手的罚球次数占投篮次数的比例。
2.2.2基于Scrapy抓取框架与AJAX技术
AJAX(Asynchronous JavaScript And XML),即使用JS语言与服务器进行异步交互,传输数据格式为XML。AJAX除了支持异步交互,另一个特点就是浏览器页面的局部刷新,由于不需要重载整个页面,不仅提高了性能,还提升了用户体验。JSON对象是JS对象的子集,它包含JS中的6种数据类型:number、string、Boolean、array、null、object。JSON字符串格式简单且字符量小,与XML相比在网络传输方面更具优势。目前,JSON已经成为各大网站交换数据的标准格式。
基于Python中json模块,通过json.dumps()方法,可以将python中的基本数据类型序列化为一种标准格式的字符串,进而可以存储或通过网络传输。通过json.loads()方法,又可以将这些标准格式的字符串反序列化为原数据类型。给服务器发送用户输入的数据,服务器将验证的结果用JSON格式的字符串发回响应,前端用JS来解析JSON数据。
Python语言体系使用Scrapy框架技术来抓取web站点与提取数据,实现数据挖掘与数据监测。我们采用AJAX技术获取球员链接的网页,再基于Scrapy框架进行网络数据抓取,获得球员数据,导出CSV文件代码如下:
Import requests
Url=”https://cba.hupu.com/teams/shanghai”
Del getHtml(url)
Try:
R=request.get(url)
raise_for_status()
encoding=R.apparent_encoding
Return R.text
Except:
Return ‘’
2.3基于Logistic Distribution与ELo算法实现成绩预测
2.3.1 ELO评分算法
ELO等级分制度是由匈牙利裔美国物理学家Elo创建的一个衡量各类对弈活动选手水平的评分方法,是当今对弈水平评估的公认权威方法,很多竞技运动都会采取 Elo 等级分制度对选手进行等级划分,如足球、篮球与棒球比赛。根据Logistic Distribution计算 PK 双方(A 和 B)对各自的胜率期望值计算公式。R_A表示A当前的积分,R_B表示B当前的积分,E_A表示A当前的胜率期望值,E_B表示B当前的胜率期望值,计算公式如下:
E_(A=1/(1+〖10〗^(((R_B-R_A))⁄400) ))
E_(B=1/(1+〖10〗^(((R_A-R_B))⁄400) ))
S_A表示实际胜负值(胜为1,平为0.5,负为0),如果S_A与A当前的胜率期望值E_A不相同,则A的Elo评分需要重新计算为R_A^new,计算公式如下:
R_A^new=R_A^old+K(S_A-R_A^old)
其中 K 值是一个常量系数,K值的大小直接关系到一局竞技活动的结束,通常水平越高的比赛中其K值应越小,从而避免少数几场比赛就能改变顶级队伍的积分排名。为让积分尽可能保持标准正态分布,将历史积分值R_A^old分为三个区间,K分别取值16、24、32。
2.3.2 特征向量提取与回归模型建立
获取数据后,利用每支队伍过去的比赛情况和Elo等级分来判断每支比赛队伍的可胜概率。在评价到每支队伍过去的比赛情况时,将使用到Team Per Game Stats、Opponent Per Game Stats和Miscellaneous Stats(以下简称为 T、O和M表)这3个表格的数据,作为代表比赛中某支队伍的比赛特征。由两支队伍的以往比赛统计情况和两个队伍各自的Elo等级分构成。使用 Python 的pandas、numpy、scipy和sklearn库Logistic Regression方法建立回归模型,計算每支比赛队伍的Elo socre,利用这些基本统计数据评价每支队伍过去的比赛情况,预测结果将显示胜算较大一方的队伍能够赢另外一方的概率。研究思路如下。
(1)数据初始化,设置回归训练时所需用到的参数变量,从T、O和M表格中读入数据,去除一些无关数据并将这三个表格通过Team属性列进行连接。
(2)获取每支队伍的Elo Score等级分函数,当在开始没有等级分时,将其赋予初始base_elo值。
(3)计算每支队伍的Elo等级分,假设获胜方提高的Elo等级分与失败方降低的Elo等级分数值相等。为了体现主场优势,主场队伍的Elo等级分在原有基础上增加100。
(4)基于数据内容前三项和Elo等级分建立每场比赛的数据集。
(5)在main 函数中调用这些数据处理函数,使用sklearn中的LogisticRegression函数建立回归模型。
(6)利用训练好的模型对比赛结果进行预测,利用模型对一场新的比赛进行胜负判断,并返回其胜利的概率。
(7)在CSV文件中保存预测结果。
研究结果与分析
3.1 球队赢分概率预测
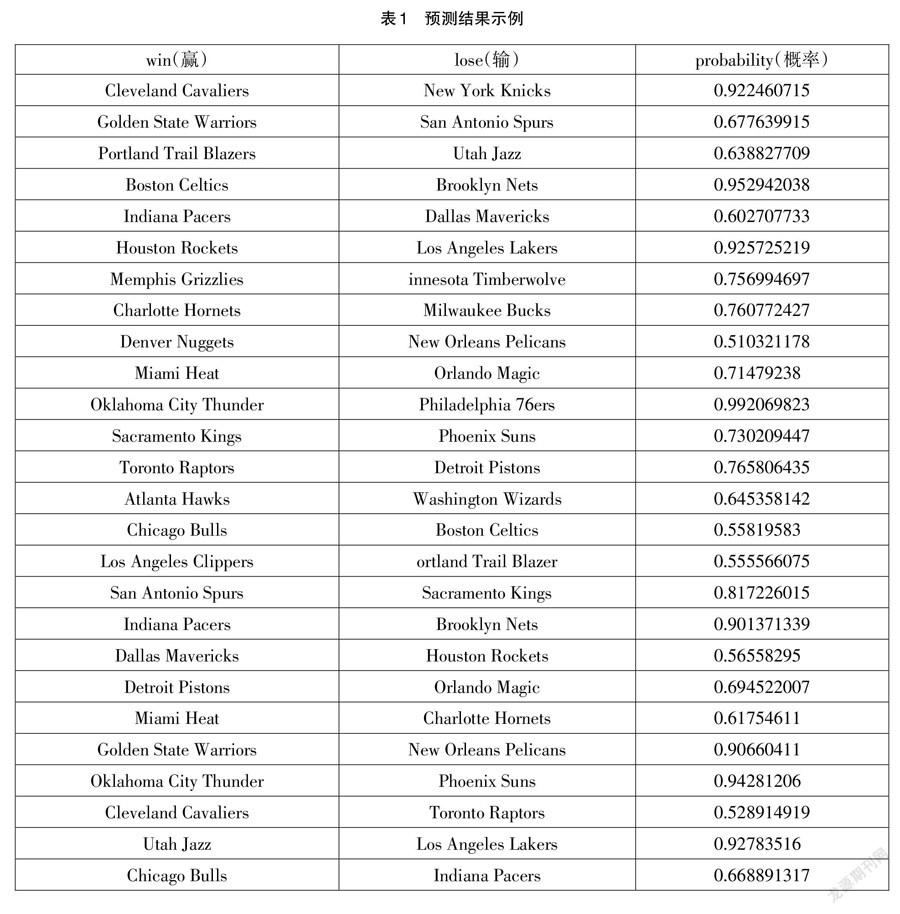
使用Python语言中pandas、numpy、scipy和sklearn库,计算每支NBA比赛队伍的Elo socre,利用这些基本统计数据评价每支队伍过去的比赛情况,并且根据国际等级划分方法Elo Score对队伍现在的战斗等级进行评分,最终结合这些不同队伍的特征判断在一场比赛中,哪支队伍能够占到优势。预测结果将显示胜算较大一方的队伍能够赢另外一方的概率,如表1所示。
结论
在下一步的研究工作中,为避免计算代价异常增大的突变,将基于Spark框架,进一步探索缓存与广播技术,提升计算并行度,并通过预处理降低预定义类的训练依赖性。本文的研究中给出胜算较大一方的队伍能够赢另外一方的概率,由于性能评价数据量有限,为实现更加准确和系统的判断,需要从统计数据网站中获取更加全面和系统的数据,并结合不同的回归、决策机器学习模型,搭建一个更加全面、预测准确率更高的模型。为此,建议中国职业篮球联赛(CBA)能顺应大数据时代的发展趋势,利用先进的数据采集与统计设备,健全我国篮球运动数据统计类型,加强竞技运动高阶数据的统计[7],为球队组建、教练用人和人才培养提供科学的指导。
参考文献
[1]马振嘉.人工智能在篮球运动中的运用分析[J].延安大学学报:自然科学版,2021,40(1):109-112.
[2]康冬阳,王晓蓉.大数据时代背景下洛阳市高校篮球队建设的促进研究[J].体育科技,2020,41(6):117-118
[3]高国贤,练碧贞,任弘.大数据时代我国篮球运动员选材理论范式危机及路径转换[J].沈阳体育学院学报,2020,39(2):101-107.
[4]张铭鑫,王新雷,练碧贞,等.“全数据”驱动下篮球教练员科学决策的案例分析——以2018-2019赛季CBA联赛广东男篮为例[J].成都体育学院学报,2020,46(6):100-106.
[5]杨莹,易卓.大数据时代下篮球运动的发展——以铜仁市为例[J].体育世界(学术版),2020(3):31-32.
[6]单曙光.篮球大数据[M].北京:世界图书出版公司,2017.99-120.
[7]蒋雪辰,左小五,陈胜,等.基于因子分析和K-Means算法对NBA得分后卫的功能性分析[J].体育研究与教育,2020,35(5):73-79.
猜你喜欢数据分析篮球大数据时代电子商务安全与数据分析平台分析电脑知识与技术(2019年30期)2019-12-16学而时习之教育界·下旬(2019年9期)2019-11-26“互联网+”背景下无偿献血档案价值利用的探讨卷宗(2019年28期)2019-11-11基于信息技术的智慧社区整体框架和功能实现科技视界(2019年23期)2019-09-28基于数据分析推动电商企业化经营实训系统性优化财讯(2019年12期)2019-06-11快乐篮球进山乡学苑创造·A版(2019年2期)2019-02-19拍篮球小学生作文辅导(2017年8期)2018-02-14浅述对企业统计工作的几点看法中国高新技术企业(2009年4期)2009-04-17 相关热词搜索: 分析研究 算法 框架